von
von LLaMA2 ist ein mächtiges Sprachmodell, das der natürlichen Sprache mit hoher Genauigkeit begegnen kann. Developed by Meta AI, es wurde auf eine immense Datensammlung von Text aus dem Internet trainiert und kann menschengemäße Antworten auf eine Vielzahl von Themen und Fragen generieren. Das Sprachmodell soll besser sein als die kostenlose Version von CHATGPT 3.5. Der Datenbestand ist Llama 2 Version Release Datum: Juli 18, 2023.
| Model | License | Commercial use? | Pretraining length [tokens] | Leaderboard score |
|---|---|---|---|---|
| Falcon-7B | Apache 2.0 | ✅ | 1,500B | 47.01 |
| MPT-7B | Apache 2.0 | ✅ | 1,000B | 48.7 |
| Llama-7B | Llama license | ❌ | 1,000B | 49.71 |
| Llama-2-7B | Llama 2 license | ✅ | 2,000B | 54.32 |
| Llama-33B | Llama license | ❌ | 1,500B | * |
| Llama-2-13B | Llama 2 license | ✅ | 2,000B | 58.67 |
| mpt-30B | Apache 2.0 | ✅ | 1,000B | 55.7 |
| Falcon-40B | Apache 2.0 | ✅ | 1,000B | 61.5 |
| Llama-65B | Llama license | ❌ | 1,500B | 62.1 |
| Llama-2-70B | Llama 2 license | ✅ | 2,000B | * |
| Llama-2-70B-chat* | Llama 2 license | ✅ | 2,000B | 66.8 |
Sprachmodell Mistral
Mistral ist ein weiteres fortschrittiges Sprachmodell, das die natürliche Sprache in Echtzeit verstehen und verarbeiten kann. Anders als LLaMA2 wurde es speziell für konversationale Schnittstellen entwickelt, wie zum Beispiel Chatbots und virtuelle Assistenten.
Mistral ist ein fortschrittliches Sprachmodell, das auf der GPT (Generative Pre-trained Transformer)-Architektur basiert. Entwickelt von führenden KI-Forschern, zeichnet sich Mistral durch seine Fähigkeit aus, natürliche Sprache zu verstehen, zu generieren und darauf zu reagieren. Diese bahnbrechende Technologie ermöglicht es, komplexe Sprachmuster zu erfassen und in Echtzeit präzise Antworten zu liefern.
Merkmale von Mistral:
- Skalierbarkeit: Mistral wurde mit einer beeindruckenden Skalierbarkeit entwickelt, was bedeutet, dass es mit verschiedenen Datenmengen arbeiten und sich an unterschiedliche Kontexte anpassen kann.
- Kontextverständnis: Dank fortschrittlicher Algorithmen ist Mistral in der Lage, den Kontext einer Konversation zu verstehen und somit nuancierte und kontextsensitive Antworten zu generieren.
- Vielseitigkeit: Das Modell ist vielseitig einsetzbar und kann in verschiedenen Branchen und Anwendungsfeldern genutzt werden, von Kundenbetreuung bis hin zu Content-Erstellung.
Anwendungen von Mistral:
- Kundenbetreuung: Unternehmen können Mistral verwenden, um automatisierte Kundensupport-Systeme zu implementieren, die schnell auf Anfragen reagieren und Probleme lösen können.
- Content-Erstellung: Redakteure und Autoren können Mistral nutzen, um Ideen zu generieren, Inhalte zu optimieren und kreative Schreibprozesse zu beschleunigen.
- Übersetzungsdienste: Mit seiner Fähigkeit, Kontext zu verstehen, kann Mistral hochwertige Übersetzungen erstellen, die nicht nur wortgetreu, sondern auch kulturell angepasst sind.
Beide Modelle verwenden komplexe Algorithmen und maschinelles Lernen, um die natürliche Sprache zu verstehen und zu analysieren. Allerdings unterscheiden sie sich in ihrer Architektur und Fähigkeiten. Während LLaMA2 auf Transformatoren basiert und Attention-Mechanismen verwendet, um bestimmte Teile des Texteintrags zu fokussieren, setzt Mistral auf eine neuartige Architektur namens „Multitask Learning. Diese ermöglicht es, Aufgaben parallel zu generieren.
Ollama Server für verschiedene Sprachmodelle
Ollama ist eine flexible Plattform, die es ermöglicht, umfangreiche Sprachmodelle lokal auszuführen und verschiedene Modelle wie Llama 2 , Mistral und mehr anzubieten. Als Werkzeug eröffnet es die Möglichkeit, eigene Modelle anzupassen und zu erstellen, was vielfältige Anwendungen wie Code-Generierung, Chat und mehr ermöglicht. Mit Ollama können Sie durch Texteingaben Code generieren und diskutieren oder es für unterschiedliche allgemeine Zwecke verwenden. Derzeit unterstützt Ollama macOS und Linux, mit der Aussicht auf zukünftige Windows-Unterstützung, und bietet einen nützlichen Blog mit Anleitungen und Updates. Erleben Sie die Zufriedenheit, eigene Sprachmodelle zu kreieren und komplexe Probleme mit Ollama zu lösen. Der Aufbau ist ähnlich wie bei ChatGPT, nur ist ohne Cloud Services. Sie können den Dienst lokal installieren, ohne ihn an externe Clouddienste anzubinden.
Was wird benötigt:
- Ein Rechner mit Linux oder Windows mit PCI-Express Slot Version 3.0 / 4.0
- Eine Grafikkarte Nvidia mit GPU Unterstützung 12GB RAM
https://www.alternate.de/html/product/1725925 mit 1 x 8-Pin (6+2) Stromanschluss - RAM-Speicher für den Rechner 16GB mindestens, besser 32GB
- Ethernet Karte für Netzwerkzugriff
- Software Ollama https://hub.docker.com/r/ollama/ollama
- https://developer.nvidia.com/cuda-downloads CUDA Treiber
- Docker Umgebung auf dem PC
- Betriebssystem Linux / Ubuntu 22.04
- Netzteil 850 Watt
https://amzn.to/4bWzQas (*) inkl. 1 x 8-Pin (6+2) Stromanschluss
Hinweis: Die Grafikkarte ist 24 cm lang und passt genau in mein vorhandenes Rechnergehäuse. Bitte prüfen ob der Platz in Deinem Rechner ebenfalls ausreichend ist. Es kann auch der Fall sein dass die Breite in einen anderen Slot hineinragt. Auch hier prüfen ob Platz vorhanden ist. Darüber hinaus hat die Karte einen Stecker 1 x 8-Pin (6+2) Stromanschluss. Das Netzteil muss das PCI-E Kabel enthalten, um die Grafikkarte mit Spannung zu versorgen. Der Verbrauch soll bei 550 Watt liegen.
Diese Anleitung setzt die vorherige Installation von Docker voraus, welche hier nicht erklärt wird. Nun müssen wir der bestehenden Docker-Installation beibringen, die GPU der Nvidia-Grafikkarte zu nutzen.Sonst werden die nachfolgenden Docker Container auf CPU Last laufen und eine sehr schlechte Performance zeigen.
Installation NVIDIA Container Toolkit
$ curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list $ sudo apt-get update $ sudo apt-get install -y nvidia-container-toolkit $ sudo nvidia-ctk runtime configure --runtime=docker $ sudo systemctl restart docker
Installation Ollama Server
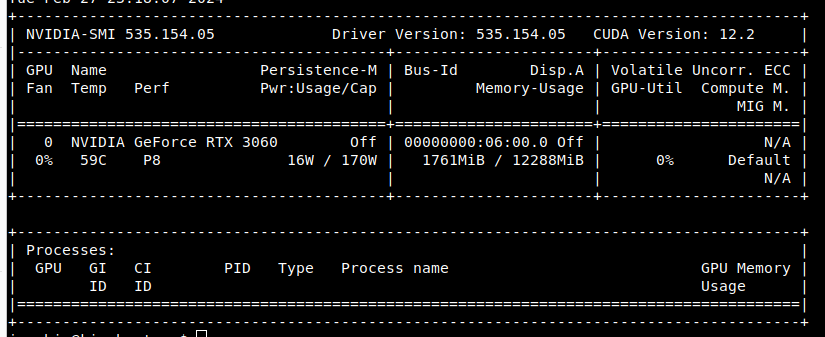
sudo docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
Es sollte nun folgende Ausgabe erscheinen:
Nun wird Ollama als Server Docker Container installiert:
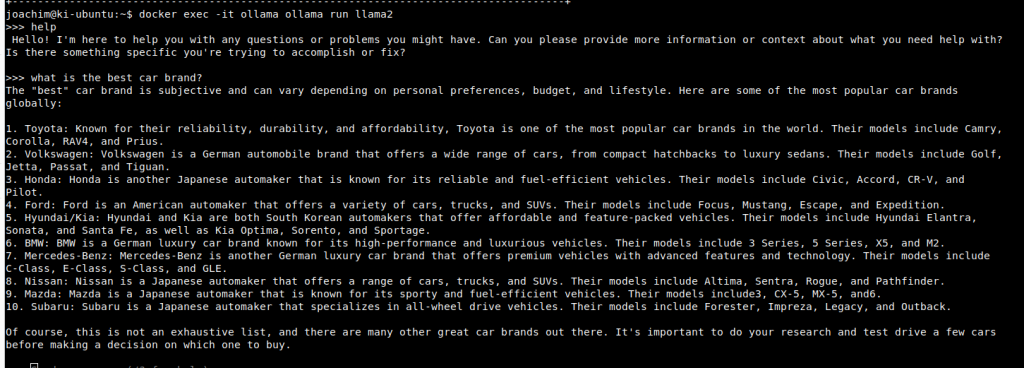
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama docker exec -it ollama ollama run llama2
Bei der Eingabe „what is the best car brand“ sollte folgende Ausgabe erfolgen und dass innerhalb Sekunden. Dauert die Antwort sehr lange und ist sehr langsam, läuft der Docker Container auf CPU und nicht auf GPU. Bitte hier nochmal die oberen Schritte überprüfen.
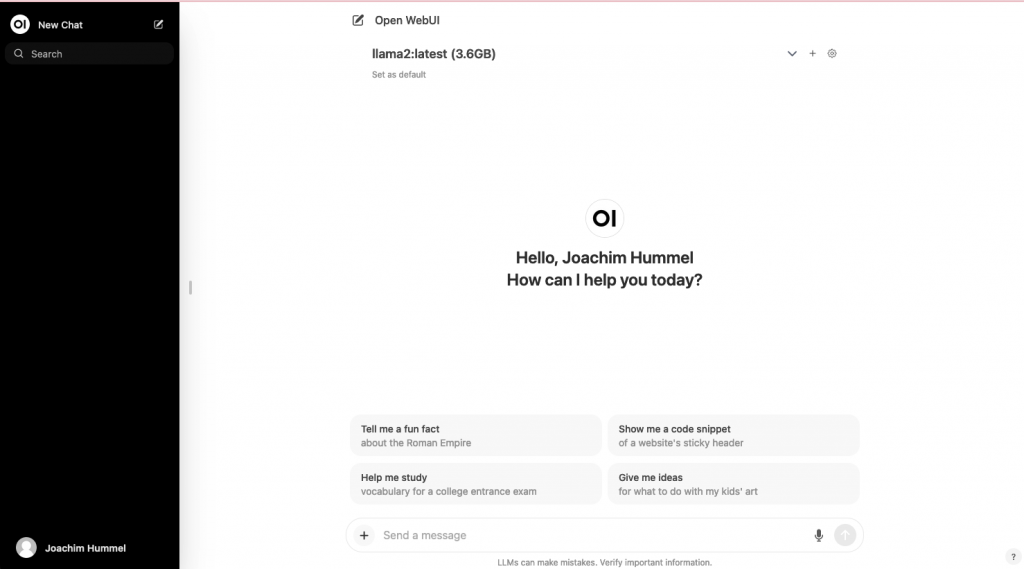
Um die Nutzung über einen Webbrowser komfortabler zu gestalten, installieren wir Open WebUI.
Open WebUI ist eine erweiterbare, funktionsreiche und benutzerfreundliche, selbst gehostete WebUI für verschiedene LLM-Läufer. Zu den unterstützten LLM-Läufern gehören Ollama- und OpenAI-kompatible APIs. Hierzu ist der Einsatz von „docker-compose“ zu empfehlen. Bitte passen Sie die Variable „OLLAMA_API_BASE_URL“ entsprechend dem IP-Netzwerk Ihres HomeLABs an. Dort wird die IP-Adresse des Ollama Server eingetragen.
version: '3.3'
services:
open-webui:
ports:
- 3005:8080
environment:
- OLLAMA_API_BASE_URL=http://192.168.1.10:11434/api
volumes:
- open-webui:/app/backend/data
container_name: open-webui
restart: always
image: ghcr.io/open-webui/open-webui:main
volumes:
open-webui:
external:
name: open-webui
Beim ersten Aufruf von http://localhost:3005 erstellt das System automatisch einen Admin-Account. Der Admin kann weitere Accounts hinzufügen, sofern die Registrierung nicht deaktiviert wurde

Das soll es mal sein, eventuell erweitere ich diesen Artikel noch mit weiteren Informationen. Bei Frage wie immer bitte die Kommentarfunktion nutzen.
Fotokredit: https://pixabay.com/de/users/alexandra_koch-621802/
Alle Artikel auf dieser Seite sind mit einem sogenannte Provision-Links. Wenn du auf so einen Verweislink klickst und über diesen Link einkaufst, bekomme ich von deinem Einkauf eine Provision. Weiterführende Infos gibt es hier unter Punkt 8 in der Datenschutzerklärung https://blog.unixweb.de/datenschutzerklaerung/